A
new
benchmark
study
released
by
Vals
AI
suggests
that
both
legal-specific
and
general
large
language
models
are
now
capable
of
performing
legal
research
tasks
with
a
level
of
accuracy
equaling
or
exceeding
that
of
human
lawyers.
The
report,
VLAIR
–
Legal
Research,
extends
the
earlier
Vals
Legal
AI
Report
(VLAIR)
from
February
2025
to
include
an
in-depth
examination
of
how
various
AI
products
handle
traditional
legal
research
questions.
That
earlier
report
evaluated
AI
tools
from
four
vendors
—
Harvey,
Thomson
Reuters
(CoCounsel),
vLex
(Vincent
AI),
and
Vecflow
(Oliver)
—
on
tasks
including
document
extraction,
document
Q&A,
summarization,
redlining,
transcript
analysis,
chronology
generation,
and
EDGAR
research.
This
follow-up
study
compared
three
legal
AI
systems
–
Alexi,
Counsel
Stack
and
Midpage
–
and
one
foundational
model,
ChatGPT,
against
a
lawyer
baseline
representing
traditional
manual
research.
All
four
AI
products,
including
ChatGPT,
scored
within
four
points
of
each
other,
with
the
legal
AI
products
performing
better
overall
than
the
generalist
product,
and
with
all
performing
better
than
the
lawyer
baseline.
The
highest
performer
across
all
criteria
was
Counsel
Stack.
Leading
Vendors
Did
Not
Participate
Unfortunately,
the
benchmarking
did
not
include
the
three
largest
AI
legal
research
platforms:
Thomson
Reuters,
LexisNexis
and
vLex.
According
to
a
spokespeople
for
Thomson
Reuters
and
LexisNexis,
neither
company
opted
into
participating
in
the
study.
They
did
not
not
say
why.
vLex,
however,
originally
agreed
to
have
its
Vincent
AI
participate
in
the
study,
but
then
withdrew
before
the
final
results
were
published.
A
spokesperson
for
vLex,
which
was
acquired
by
Clio
in
June,
said
that
it
chose
not
to
participate
in
the
legal
research
benchmark
because
it
was
not
designed
for
enterprise
AI
tools.
The
spokesperson
said
vLex would
be
open
to
joining
future
studies
that
fit
its
focus.
Overview
of
the
Study
Vals
AI
designed
the
Legal
AI
Report
to
assess
AI
tools
on
a
lawyer-comparable
benchmark,
evaluating
performance
across
three
weighted
criteria:
-
Accuracy
(50%
weight)
–
whether
the
AI
produced
a
substantively
correct
answer. -
Authoritativeness
(40%)
–
whether
the
response
cited
reliable,
relevant,
and
authoritative
sources. -
Appropriateness
(10%)
–
whether
the
answer
was
well-structured
and
could
be
readily
shared
with
a
client
or
colleague.
Each
AI
product
and
the
lawyer
baseline
answered
210
questions
spanning
nine
legal
research
types,
from
confirming
statutory
definitions
to
producing
50-state
surveys.
Key
Findings
-
AI
Now
Matches
or
Beats
Lawyers
in
Accuracy
Across
all
questions,
the
AI
systems
scored
within
four
percentage
points
of
one
another
and
an
average
of
seven
points
above
the
lawyer
baseline.
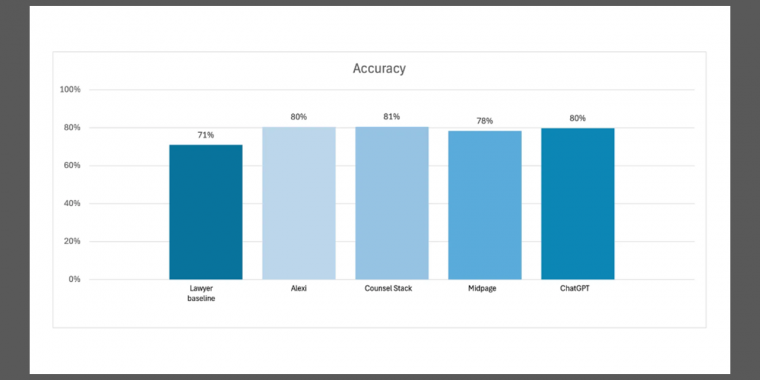
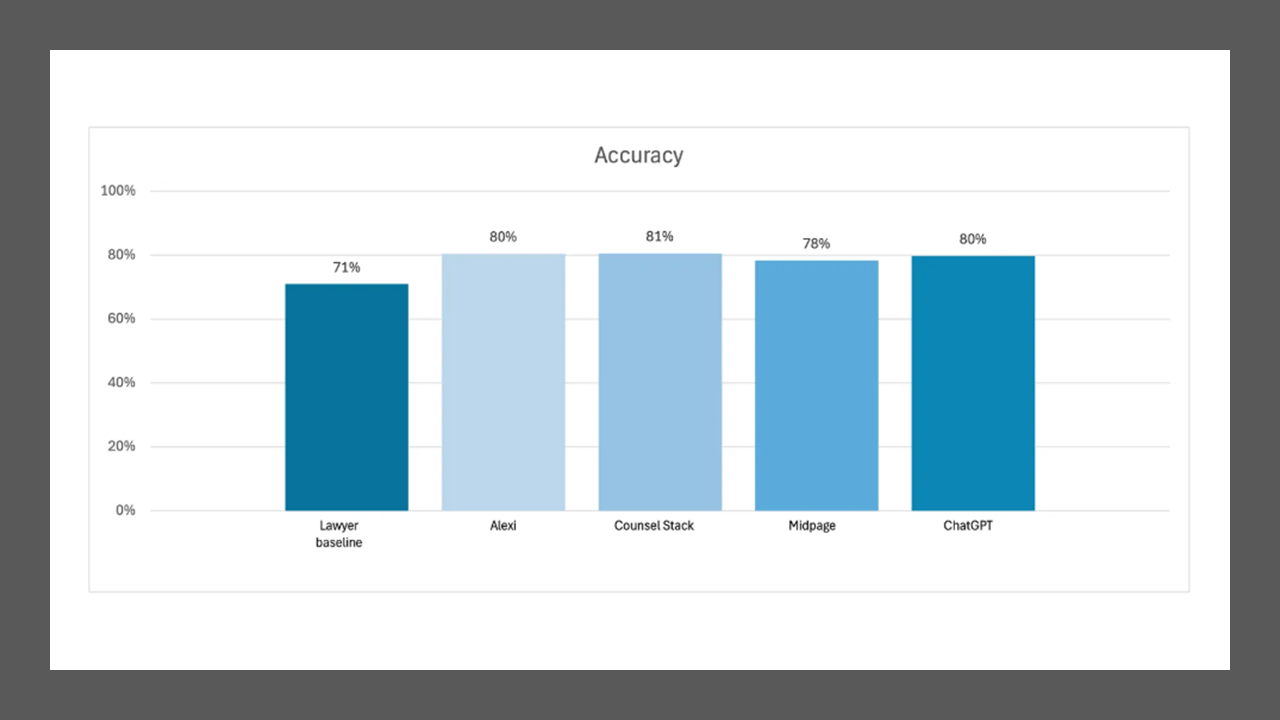
-
Lawyers
averaged
71%
accuracy. -
Alexi:
80% -
Counsel
Stack:
81% -
Midpage:
79% -
ChatGPT:
80%.
When
grouped,
both
legal-specific
and
generalist
AIs
achieved
the
same
overall
accuracy
of
80%,
outperforming
lawyers
by
nine
points.
Significantly,
for
five
of
the
question
types,
on
average,
the
generalist
AI
product
provided
a
more
accurate
response
than
the
legal
AI
products,
and
one
question
type
where
the
accuracy
was
scored
the
same.
“Both
legal
AI
and
generalist
AI
can
produce
highly
accurate
answers
to
legal
research
questions,”
the
report
concludes.
Even
so,
the
report
found
multiple
instances
where
the
legal
AI
products
were
unable
to
produce
a
response.
This
was
due
to
either
technical
issues
or
deemed
lack
of
available
source
data.
“Pure
technical
issues
only
arose
with
Counsel
Stack
(4)
and
Midpage
(3),
where
no
response
was
provided
at
all.
In
other
cases,
the
AI
products
acknowledged
they
were
unable
to
locate
the
right
documents
to
provide
a
response
but
still
provided
some
form
of
response
or
explanation
as
to
why
the
available
sources
did
not
support
their
ability
to
provide
an
answer.”
-
Legal
AI
Leads
in
Authoritativeness
While
ChatGPT
matched
its
legal-AI
rivals
on
accuracy,
it
lagged
in
authority
—
scoring
70%
to
the
legal
AIs’
76%
average.
The
difference,
Vals
AI
said,
reflects
access
to
proprietary
legal
databases
and
curated
citation
sources,
which
remain
differentiators
for
legal-domain
systems.
“The
study
outcomes
support
a
common
assumption
that
access
to
proprietary
databases,
even
if
composed
mainly
of
publicly
available
data,
does
result
in
differentiated
products.”
-
Jurisdictional
Complexity
Remains
Hard
for
All
All
systems
struggled
with
multi-jurisdictional
questions,
which
required
synthesizing
laws
from
multiple
states.
Performance
dropped
by
11
points
on
average
compared
to
single-state
questions.
Counsel
Stack
and
Alexi
tied
for
best
performance
on
these,
while
ChatGPT
trailed
closely.
-
AI
Excels
at
Certain
Tasks
Beyond
Human
Speed
The
AI
products
outperformed
the
lawyer
baseline
on
15
of
21
question
types
—
often
by
wide
margins
when
tasks
required
summarizing
holdings,
identifying
relevant
statutes,
or
sourcing
recent
caselaw.
For
example,
AI
responses
were
completed
in
seconds
or
minutes,
compared
to
lawyers’
average
1,400-second
response
latency
(~23
minutes).
And
where
the
AI
products
outperformed
the
humans
on
individual
questions,
they
did
so
by
a
wide
margin
–
an
average
of
31
percentage
points.
-
Human
Judgment
Still
Matters
Lawyers
outperformed
AI
in
roughly
one-third
of
question
categories,
particularly
those
requiring
deep
interpretive
analysis
or
nuanced
reasoning,
such
as
distinguishing
similar
precedents
or
reconciling
conflicting
authorities.
These
areas
underscore,
as
the
report
put
it,
“the
enduring
edge
of
human
judgment
in
complex,
multi-jurisdictional
reasoning.”
Methodology
The
study
was
conducted
blind
and
independently
evaluated
by
a
consortium
of
law
firms
and
academics.
Each
participant
answered
identical
research
questions
crafted
to
mirror
real-world
lawyer
tasks.
Evaluators
graded
every
response
using
a
detailed
rubric
(which
the
report
includes).
The
AI
vendors
represented
were:
-
Alexi
–
legal
research
automation
startup
(founded
2017). -
Counsel
Stack
–
open-source
legal
knowledge
platform. -
Midpage
–
AI
research
and
brief-generation
tool. -
ChatGPT
–
generalist
large
language
model
(GPT-4).
Vals
AI
cautioned
that
the
benchmark
covers
general
legal
research
only,
not
tasks
such
as
drafting
pleadings
or
generating
formatted
citations.
And,
as
the
report
notes,
“Legal
research
encompasses
a
wide
range
of
activities
…
but
there
is
not
always
a
single
correct
answer
prepared
in
advance.”
Bottom
Line
The
VLAIR
–
Legal
Research
study
reinforces
what
many
in
the
legal
tech
industry
have
already
observed,
which
is
that
AI
systems
–
both
generalist
and
domain-trained
–
are
rapidly
closing
the
quality
gap
with
human
legal
researchers,
particularly
in
accuracy
and
efficiency.
Yet,
the
edge
remains
with
legal-specific
AIs
in
trustworthiness
and
source
citation,
suggesting
that
proprietary
data
access
is
the
next
competitive
frontier.
For
law
firms,
corporate
legal
departments,
and
AI
vendors
alike,
the
study
serves
as
a
transparent
benchmark
–
a
rare
apples-to-apples
comparison
—
for
understanding
where
today’s
models
shine
and
where
human
expertise
remains
indispensable.
Even
so,
the
study
is
weakened
by
the
failure
of
the
three
biggest
AI
legal
research
platforms
to
participate.
This
is
not
the
fault
of
Vals
AI,
but
it
leaves
one
wondering
why
the
big
three
all
opted
out.