*
Government
says
tariff
refund
system
40
percent
to
80
percent
complete
which
is…
quite
the
spread.
Almost
a
“they’re
just
making
stuff
up”
kind
of
estimate.
[Reuters]
*
In
a
reminder
that
everything
is
discoverable,
Live
Nation
employees
messaged
each
other
over
Slack
to
talk
about
robbing
fans.
[New
York
Post]
*
Generative
AI
still
occupies
legal
gray
zones.
[Legaltech
News]
*
Judge
Pauline
Newman
appeals
to
the
Supreme
Court
over
her
colleagues’
“pocket
impeachment”
effort
to
strip
her
of
her
life
tenured
job.
[The
Hill]
*
DOJ
spent
months
repeatedly
emailing
the
wrong
address
asking
for
state
election
data.
[Democracy
Docket]
Sidley
Austin
Takes
The
Nonequity
Plunge:
Welcome
to
the
fold,
“Partner”!
DLA
Piper
Abandons
The
Verein
Structure:
Will
other
firms
adopt
the
move?
From
Calling
It
Quits
To
Running
For
Office!:
Former
DOJ
attorney
Julie
Le
is
running
for
Congress.
Costco
Customers
Fight
For
Savings!:
There’s
a
class
action
suit
for
customers
to
get
their
share
of
the
potential
tariff
refund.
We
know,
in
a
world
of
uncertainties,
AI
is
coming
for
all
of
us
in
different
ways.
Trying
to
keep
up
with
all
the
changes
(and
I
am
not
even
mentioning
our
overseas
adventures)
is
exhausting,
overwhelming,
and
frustrating.
How
to
cope?
More
reliance
on
AI?
The
Wall
Street
Journal
recently
ran
an
article
comparing
the
three
large
learning
machines
(Claude,
Gemini,
and
OpenAI)
in
a
kind
of
LLM
legal
writing
Olympics.
The
results
were
fascinating.
Each
of
the
three
competitors
was
better
in
some
ways,
and
worse
in
others.
Each
bot
had
quirks
of
its
own.
How
to
tell
a
bot
from
a
human?
In
this
admittedly
unscientific
test,
one
way
to
tell
a
bot
from
a human
was
vocabulary.
If
it
sounds
like
it’s
“a
panicked
college
freshman
trying
to
sound
profound,”
it’s
a
bot.
If
the
article,
memo,
or
document
starts
out
by
telling
the
reader
what
it’s
about,
it’s
a
bot.
All
three
bots
hedged,
reluctant
to
give
opinions.
“On
the
one
thing
…
on
the
other.”
That
wishy-washy
language
is
not
what
clients
are
paying
for.
They
are
paying
for
our
opinions
and
our
advice
with
available
options
about
how
to
proceed.
Clients
want
clear
directions
and
advice;
save
the
erudite
for
law
review
articles.
The
time
will
come,
sooner
rather
than
later,
when
bot
writing
will
be
essentially
indistinguishable
from
what
we
humans
write.
It’s
about
to
become
a
lot
more
difficult
to
choose
the
real
from
the
artificial.
You
are
not
a
bot,
so
don’t
write
like
one.
Clients
do
not
want
to
read
(or
pay
for)
pages
and
pages
of
legal
gobbledygook
that,
in
the
end,
only
confuse
the
reader
while
the
meter
runs.
Perhaps
for
law
review
articles
and
other
scholarly
compositions,
more
is
more,
but
for
the
everyday
lawyer
who
is
just
trying
to
KISS
(Keep
It
Simple
Stupid),
twisting
yourself
into
a
legal
literary
pretzel
does
no
one
any
good,
especially
the
reader.
Get
to
the
point
quickly
before
eyes
glaze
over
and
the
reader
snores.
On
another
AI
topic,
is
a
lawsuit
really
final
even
if
it’s
been
settled
and
the
case
dismissed
with
prejudice?
No,
not
according
to
ChatGPT,
a
font
of
legal
(mis)information
(ahem).
Nippon
Life
Insurance
has
sued
OpenAI
in
federal
court
in
Chicago,
alleging
that
OpenAI
engaged
in
UPL,
that
is,
the
unauthorized
practice
of
law.
The
basis?
ChatGPT
advised
the
settling
plaintiff
in
the
underlying
disability
case
that
she
could
reopen
that
dismissed
lawsuit.
(She
had
a
case
of
settler’s
remorse,
not
that
any
settling
party
has
ever
felt
that
way.)
Nippon’s
complaint
alleges
that
ChatGPT
is
not
an
attorney
and
therefore
cannot
give
legal
advice.
The
plaintiff
thought
that
her
attorney
(a
human,
not
a
bot)
had
given
her
bad
advice
about
whether
she
could
indeed
reopen
the
dismissed
case.
So,
she
went
“attorney
shopping”
and
looked
to
ChatGPT
for
advice.
Guess
what?
ChatGPT
told
the
women
that
indeed
she
had
been
given
wrong
advice.
The
woman
fired
her
counsel
and
looked
solely
to
AI
for
advice
and
moved
to
reopen
the
closed
case.
After
that
was
denied,
she
filed
a
new
case
and
dozens
of
motions
allegedly
using
AI
again,
including
a
hallucinated
case.
OpenAI
says
that
Nippon’s
case
lacks
merit.
Really?
Who
is
responsible
for
a
bot’s
conduct?
Certainly
not
the
bot,
at
least
not
so
far.
On
how
many
levels
is
this
scary?
Let
me
count
some
of
the
ways.
UPL
is
a
big
problem
for
bar
disciplinary
agencies.
Too
many
nonbarred
peeps
in
the
field.
How
to
enforce
UPL
against
a
bot?
That’s
trying
to
nail
Jell-O
to
a
tree.
How
could
the
disciplinary
process
be
used
to
outlaw
the
use
of
AI?
Should
it?
How
can
lawyers
protect
themselves,
if
at
all,
from
AI
dissing
their
advice
resulting
in
an
unhappy
client
who
fires
the
lawyer
and
then
files
a
complaint
with
the
bar
based
on
that
allegedly
bad
advice?
Which,
in
this
case,
was
correct
advice?
How
does
the
court
order
a
bot
to
pay
a
Rule
11
sanction?
Is
your
head
spinning
yet?
Reliance
on
incorrect
information
from
ChatGPT
or
any
other
bot
that
leads
to
frivolous
lawsuits,
both
in
court
and
in
unjustified
bar
discipline
cases,
only
makes
the
legal
system
grind
ever
more
slowly
and
lead
to
even
more
crap
filings.
Is
reliance
on
a
bot
merely
general
legal
information
or
specific
legal
advice?
Pass
the
Pepto,
please.
Or
an
Excedrin.
Or
maybe
both.
Perhaps
a
bot
can
suggest
what
to
take.
Or
would
that
be
practicing
medicine
without
a
license?
Jill
Switzer
has
been
an
active
member
of
the
State
Bar
of
California
for
over
40
years.
She
remembers
practicing
law
in
a
kinder,
gentler
time.
She’s
had
a
diverse
legal
career,
including
stints
as
a
deputy
district
attorney,
a
solo
practice,
and
several
senior
in-house
gigs.
She
now
mediates
full-time,
which
gives
her
the
opportunity
to
see
dinosaurs,
millennials,
and
those
in-between
interact
—
it’s
not
always
civil.
You
can
reach
her
by
email
at [email protected].
The
AI
legal
research
startup
Descrybe
today
launched
a
“legal
reasoning”
product,
DescrybeLM,
that
it
says
outperforms
leading
general-purpose
AI
models
on
a
standardized
legal
reasoning
benchmark
—
and
it
is
publishing
the
methodology
and
scoring
data
to
invite
scrutiny.
The
company
also
launched
an
all-new
website
that
features
the
new
product
while
also
retaining
all
the
functionality
of
its
prior
“Legal
Research
Toolkit,”
which
includes
tools
for
conducting
legal
research
by
concept,
keyword,
case
name,
citation,
and
legal
issue.
As
the
company
says,
DescrybeLM
and
the
Legal
Research
Toolkit
are
“built
to
work
together,”
with
the
latter
used
to
find
the
relevant
law
that
bears
on
a
question
and
the
former
then
enabling
users
to
reason
through
it
against
the
specific
facts
of
the
matter
at
hand.
Benchmarking
Against
General
AI
The
company
tested
its
new
system
against
ChatGPT
5.2,
Claude
Opus
4.5
and
Gemini
3
Pro
on
200
questions
from
the
National
Conference
of
Bar
Examiners
MBE
Complete
Practice
Exam.
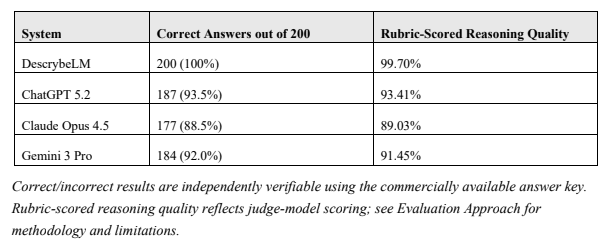
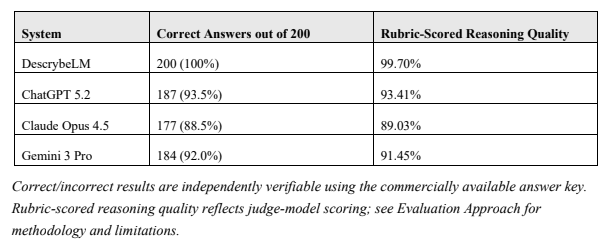
DescrybeLM
answered
all
200
correctly.
The
general-purpose
models
each
missed
between
13
and
23
questions,
achieving
accuracy
rates
ranging
from
88.5%
to
93.5%.
Rubric-scored
reasoning
quality
—
a
separate
measure
evaluating
whether
systems
correctly
identified
governing
legal
rules
and
applied
them
to
the
facts
—
followed
a
similar
pattern.
DescrybeLM
scored
99.70%
on
that
dimension.
ChatGPT
5.2
scored
93.41%,
Gemini
3
Pro
scored
91.45%,
and
Claude
Opus
4.5
scored
89.03%.
A
central
fcous
of
the
study
was
not
just
whether
AI
systems
get
legal
questions
wrong,
but
rather
how
they
get
them
wrong.
Among
the
52
incorrect
outputs
produced
by
the
three
general-purpose
models,
49
were
flagged
as
“confidently
wrong”
—
assertive,
fluent,
well-structured
responses
that
gave
no
signal
of
uncertainty.
The
dominant
failure
patterns
were
applying
the
wrong
legal
standard
to
the
facts,
or
applying
the
correct
standard
incorrectly.
“When
these
systems
were
wrong,
they
were
confidently
wrong,”
the
benchmarking
study
said.
“Among
the
52
total
incorrect
outputs,
the
dominant
failure
patterns
applied
the
wrong
legal
standard
or
misapplied
the
correct
one,
while
presenting
the
analysis
in
fluent,
well-structured
prose.
These
are
precisely
the
errors
that
impose
the
highest
verification
burden
on
practitioners.”
The
study
also
found
that
cross-checking
between
general-purpose
models
is
an
unreliable
safeguard.
Across
the
200
questions,
40
were
missed
by
at
least
one
of
the
three
models,
but
only
one
question
was
missed
by
all
three.
Because
errors
were
largely
non-overlapping
and
unpredictable,
model
disagreement
does
n0t
reliably
identify
which
output
is
correct,
it
only
signals
that
verification
is
needed.
The
scoring
log
found
that
two
general-purpose
models
—
Claude
Opus
4.5
and
Gemini
3
Pro
—
were
flagged
for
overconfidence
on
correct
outputs
as
well
as
incorrect
ones.
Claude
Opus
4.5
received
three
overconfidence
flags
total,
one
on
a
wrong
answer
and
two
on
correct
ones.
Gemini
3
Pro
received
one
overconfidence
flag
on
a
correct
answer.
ChatGPT
5.2
and
DescrybeLM
received
zero
overconfidence
flags
across
all
200
outputs.
The
study
interprets
this
as
a
model-level
stylistic
tendency,
not
simply
a
byproduct
of
being
wrong.
A
system
that
applies
the
same
assertive
tone
regardless
of
whether
its
answer
is
correct,
the
white
paper
argues,
gives
legal
practitioners
less
reliable
signal
from
output
confidence
alone.
“We
had
a
thesis
that
purpose-built
legal
AI
produces
meaningfully
different
results
for
legal
reasoning
tasks,”
said
Kara
Peterson,
Descrybe’s
cofounder
and
CEO.
“Legal
professionals
deserve
to
make
tool
decisions
based
on
real
evidence,
which
can
be
hard
to
find.
So,
we
tested
ourselves.”
Peterson
said
she
understands
that
vendor-produced
benchmarks
invite
scrutiny.
“That’s
why
we
published
our
methodology
and
invite
anyone
to
replicate
it,”
she
said.
What’s
Behind
DescrybeLM
Descrybe
describes
the
focus
of
this
study,
its
new
DescrybeLM,
as
a
legal
reasoning
engine
and
drafting
workspace.
It
enables
users
to
receive
authority-grounded
analysis
to
complex
legal
questions
and
then
to
refine
that
analysis
through
clarifying
follow-ups.
(Descrybe
invited
me
to
test
the
new
product
in
advance
of
today’s
launch.
Because
of
my
own
tight
schedule,
I
was
unable
to
do
so,
but
I
still
plan
to
at
a
later
point
and
will
report
back
when
I
do.)
It
is
built,
the
company
says,
on
a
curated
primary
law
corpus
of
more
than
100
million
structured
records,
processed
at
a
scale
requiring
more
than
100
billion
tokens
of
preparation.
The
system
is
designed
to
produce
verification-friendly
outputs
that
include
clear
rule
statements,
application
to
key
facts,
and
structured
reasoning.
You
can
see
it
demonstrated
in
this
video:
“Most
AI
tools
are
built
for
general
use
and
adapted
for
law,”
said
Richard
DiBona,
cofounder
and
CTO.
“DescrybeLM
was
built
differently:
from
the
foundation
up,
specifically
for
legal
reasoning,
on
more
than
100
million
structured
records
individually
cleaned
and
organized
for
that
purpose.”
In
the
study,
the
company
chose
to
benchmark
only
against
general-purpose
models
rather
than
other
AI
platforms
specifically
built
for
legal
research.
I
asked
Peterson
why
that
was.
She
explained
that
the
company’s
central
question
was
what
distinguishes
foundation
models
from
purpose-built
tools,
and
that
the
best
way
to
test
that
thesis
was
to
put
themselves
directly
in
comparison
against
those
models.
Peterson
emphasized
that
she
strongly
encourages
other
legal
AI
vendors
to
run
the
same
benchmark
using
the
same
methodology.
Caveats
the
Company
Itself
Raises
Descrybe
is
transparent
about
the
possible
limitations
of
its
own
study,
which
it
spells
out
in
the
report.
Most
notably,
the
company
says
that
it
cannot
rule
out
that
some
or
all
of
the
200
questions
appeared
in
the
training
data
of
the
evaluated
systems,
including
its
own
DescrybeLM.
The
MBE
Complete
Practice
Exam
is
a
commercially
available
product.
That
caveat
applies
equally
to
all
systems
tested,
but
a
perfect
score
on
a
published
question
set
will
invite
more
scrutiny
than
a
score
of,
say,
93%.
The
study
also
discloses
that
fine-tuning
performed
on
DescrybeLM
before
the
benchmark
was
conducted
on
a
separate
NCBE
product,
not
the
question
set
used
in
the
evaluation,
and
that
the
NCBE
answer
key
was
not
provided
to
the
system
during
testing.
Among
other
limitations:
the
benchmark
covers
only
multiple-choice
legal
reasoning
and
does
not
test
drafting,
jurisdiction-specific
research,
citation
accuracy
or
other
real-world
legal
workflows.
The
evaluation
was
conducted
entirely
by
the
team
that
built
DescrybeLM.
Scoring
was
executed
by
an
AI
judge
model
—
specifically,
GPT-5.2
extra
high
reasoning,
which
is
in
the
same
model
family
as
one
of
the
evaluated
systems.
And
each
question
was
run
only
once
per
system,
meaning
the
results
do
not
come
with
confidence
intervals
or
variance
data.
On
the
rubric
design,
the
company
acknowledges
the
possibility
of
unconscious
bias
favoring
DescrybeLM’s
output
style,
but
says
it
mitigated
that
risk
through
three
measures:
the
rubric
was
authored
by
a
human
subject-matter
expert
and
pre-committed
before
scoring
began;
all
outputs
were
anonymized
before
the
judge
model
applied
the
rubric;
and
the
same
rubric,
judge
prompt,
and
settings
were
applied
identically
across
all
800
outputs.
DescrybeLM’s
perfect
accuracy
score
did
not
imply
perfect
reasoning.
Twenty-seven
of
its
outputs
received
rubric
scores
below
100,
mostly
for
incomplete
distractor
discussion
or
alternative
doctrinal
framing
—
that
is,
reaching
the
correct
answer
via
a
different
but
defensible
legal
standard
than
the
one
emphasized
by
the
reference
answer.
No
DescrybeLM
output
was
flagged
for
wrong
rule,
misapplied
rule,
misread
key
fact,
or
internal
contradiction.
Inviting
Replication
As
noted,
the
company
has
published
its
full
methodology,
scoring
rubric,
standardized
prompt
and
a
per-output
scoring
log
covering
all
800
model
outputs
across
the
four
systems.
The
NCBE
question
set
is
commercially
available,
and
Descrybe
says
any
researcher
or
vendor
can
purchase
it
and
independently
replicate
the
benchmark.
Because
of
model
non-determinism
and
ongoing
provider
updates,
exact
numerical
replication
is
unlikely,
the
company
says,
but
directional
replication,
including
rank
ordering
and
approximate
accuracy
ranges,
is
the
expected
standard.
“I’ve
worked
in
legal
technology
for
a
long
time,”
said
Ken
Friedman,
founder
of
the
legal
tech
practice
group
at
law
firm
L&F
Brown
and
a
strategic
advisor
to
the
company.
“It’s
rare
to
see
something
that
genuinely
stops
you
in
your
tracks.
When
I
saw
DescrybeLM
answer
all
200
multistate
bar
exam
questions
correctly
while
ChatGPT,
Claude
and
Gemini
each
missed
double
digits,
that’s
exactly
what
happened.”
The
second
constant
—
which
probably
gave
rise
to
the
first
—
is
that
Costco
members
are
serious
about
their
money.
Despite
the
President’s
repeated
claims
that
the
tariffs
were
amazing
for
the
economy,
many
a
laughing
economist
has
stated
otherwise.
Even
if
some
companies
were
willing
to
absorb
parts
of
the
raised
costs,
the
lion’s
share
of
the
burden
would
be
lifted
by
consumers
paying
higher
prices.
A
Costco
customer
has
filed
a
class
action
lawsuit
against
the
wholesale
retailer
in
an
attempt
to
force
the
company
to
refund
customers
who
paid
higher
prices
for
imported
goods
as
a
result
of
President
Donald
Trump’s
tariffs.
The
lawsuit,
filed
in
an
Illinois
federal
court
Wednesday,
seeks
to
compel
Costco
to
pass
along
refunds
to
customers
that
it
may
obtain
from
the
government
after
the
U.S.
Supreme
Court
struck
down
Trump’s
tariffs.
Quick,
somebody
get
that
guy
a
$1.50
hotdog
and
soda
combo
on
the
house!
The
first
thing
to
point
out
is
that
the
class
action
suit
hinges
on
a
big
if:
Costco
has
to
successfully
get
the
refund
from
the
government
before
they
can
give
members
their
share.
Some
companies
may
opt
to
settle
on
a
portion
of
they
money
they
could
be
entitled
to
to
get
some
of
the
money
upfront
and
avoid
drawn
out
legal
battles.
Were
Costco
to
settle,
the
suit
may
hinge
on
what
amount
of
the
setttlement
customers
are
entitled
to.
Day
in
court
or
not,
Costco’s
CEO
Ron
Vachris
promised
that
they
will
“retur[n]
the
value
to
Costco
members
through
lower
prices
and
better
values.”
What
did
we
learn
yesterday,
folks?
That’s
right
—
no
handshake
contracts!
This
isn’t
to
throw
dirt
on
Costco’s
name
in
any
way,
as
their
recent
price
cuts
suggest
Vachris
&
management
are
putting
our
savings
where
their
mouths
are,
but
some
legal
pressure
won’t
hurt
the
chances
of
seeing
some
part
of
the
tarriff
refund.
Shouldn’t
be
too
much
sweat
off
of
Costco’s
back
anyway
—
whatever
money
customers
get
will
be
used
to
buy
more
rotisserie
chickens.
Chris
Williams
became
a
social
media
manager
and
assistant
editor
for
Above
the
Law
in
June
2021.
Prior
to
joining
the
staff,
he
moonlighted
as
a
minor
Memelord™
in
the
Facebook
group Law
School
Memes
for
Edgy
T14s
.
He
endured
Missouri
long
enough
to
graduate
from
Washington
University
in
St.
Louis
School
of
Law.
He
is
a
former
boat
builder
who
is
learning
to
swim
and
is
interested
in
rhetoric,
Spinozists
and
humor.
Getting
back
in
to
cycling
wouldn’t
hurt
either.
You
can
reach
him
by
email
at [email protected]
and
by
tweet
at @WritesForRent.
You
have
the
fact
that
they’ve
had
years
to
prepare
for
this,
and
then
you
have
the
fact
that
they
almost
said
nothing
for
a
few
days
at
all
when
all
the
files
first
came
out.
If
you
have
got
an
unexploded
bomb
such
as
the
Epstein
files,
you
need
to
have
a
fully
worked
plan
across
various
scenarios
for
if
or
when
that
bomb
does
go
off.
— A
legal
PR
firm
leader,
in
anonymous
comments
given
to
Law.com
International,
concerning
the
Biglaw
firms
that
were
left
fumbling
from
a
public
relations
stance
when
revelations
from
the
Epstein
files
were
disclosed,
illustrating
relationships
law
firm
leaders
had
with
the
late
sex
offender.
Staci
Zaretsky is
the
managing
editor
of
Above
the
Law,
where
she’s
worked
since
2011.
She’d
love
to
hear
from
you,
so
please
feel
free
to email her
with
any
tips,
questions,
comments,
or
critiques.
You
can
follow
her
on Bluesky, X/Twitter,
and Threads, or
connect
with
her
on LinkedIn.
Another
day,
another
Biglaw
firm
tinkering
with
the
partnership
model.
Yet
another
firm
is
joining
the
growing
ranks
experimenting
with
a
nonequity
partner
tier,
offering
lawyers
the
prestige
of
partnership
title
without
the
full
financial
buy-in
(or
payoff)
that
traditionally
comes
with
it.
As
more
firms
rethink
compensation
structures,
retention
strategies,
and
the
path
to
equity,
the
expansion
of
nonequity
partnership
continues
to
signal
a
broader
shift
in
how
Biglaw
defines
partnership
in
the
first
place.
Sources
tell
Above
the
Law
that
yesterday
afternoon,
Sidley
—
the
No.
6
firm
on
the
2025
Am
Law
100
—
notified
all
lawyers
about
its
new
income
partner
tier.
Here’s
an
excerpt
from
that
firmwide
email:
Change
in
Biglaw
rarely
arrives
without
a
little
grumbling,
and
the
rollout
of
a
new
nonequity
partnership
tier
is
no
exception.
Associates
who
once
envisioned
a
more
straightforward
path
to
equity
are
now
grappling
with
the
reality
of
an
extra
rung
on
the
ladder.
“Associates
and
counsel
who
are
up
this
year
got
no
prior
warning
that
a
nonequity
tier
was
even
on
the
table
and
are
furious,”
a
source
told
ATL.
Still,
as
firms
continue
to
normalize
these
structures
across
the
industry,
lawyers
may
ultimately
have
little
choice
but
to
get
used
to
the
new
status
quo,
where
the
title
of
“partner”
doesn’t
necessarily
mean
what
it
used
to.
Best
of
luck
to
Sidley
as
it
moves
forward
with
its
income
partnership
program.
Is
your
firm
planning
to
increase
its
nonequity
partnership
ranks?
Please
please
text
us
(646-820-8477)
or email
us and
let
us
know.
Thanks.
Staci
Zaretsky is
the
managing
editor
of
Above
the
Law,
where
she’s
worked
since
2011.
She’d
love
to
hear
from
you,
so
please
feel
free
to email her
with
any
tips,
questions,
comments,
or
critiques.
You
can
follow
her
on Bluesky, X/Twitter,
and Threads, or
connect
with
her
on LinkedIn.
Legalweek‘s
traditional
judicial
panel
is
usually
a
reliable
deep-dive
into
e-discovery
and
trial
tech:
thorough
but
frankly
a
little
dry.
This
year
was
something
else
entirely.
This
year’s
judges
drove
home
the
clear
and
present
danger
to
our
judiciary,
the
rule
of
law,
our
profession,
and
our
society.
And
the
threat
cannot
be
overstated.
The
Panel
The
panel
was
composed
of
four
current
female
federal
district
court
judges
from
across
the
country.
Before
they
were
introduced,
a
warning
was
given
that
they
planned
to
play
a
graphic
audio
recording
containing
foul
language
that
might
be
disturbing.
But
that
video
paled
in
comparison
to
the
living
hell
these
judges
are
living
in,
created
by
those
who
disagree
or
don’t
like
their
rulings.
Judge
Esther
Salas
moderated
the
panel
and
opened
the
presentation
by
describing
in
riveting
detail
the
murder
of
her
only
child
and
almost
fatal
shooting
of
her
husband
by
a
disgruntled
lawyer.
You
could
have
heard
a
pin
drop
as
she
talked
about
what
happened
and
its
impact.
And
that
was
only
the
beginning.
The
panel,
also
composed
of
Judge
Kenly
Kiya
Kato,
Judge
Karoline
Mehalchick,
and
Judge
Mia
Roberts
Perez,
described
a
series
of
threats,
intimidation,
doxing,
swatting,
and
misinformation
directed
not
only
at
themselves
but
also
throughout
our
judiciary.
It’s
a
poison
that
stems
from
the
highest
level
of
government
who
disrespect
our
judges
and
their
rulings
and
resort
to
name
calling
and
insults.
All
of
which
encourages
other
elements
of
our
society
to
action.
People
who
are
convinced
by
the
rhetoric
that
a
judge
who
rules
a
certain
way
deserves
what
they
get.
And
according
to
the
judges,
it
filters
down
to
not
just
cases
that
carry
some
political
ramifications
but
also
to
ordinary
matters
and
litigants.
The
message
is
to
spew
hatred
and
violence
and
ignore
rulings.
What
Our
Judges
Are
Facing
The
judges
told
stories
of
things
like
hundreds
of
unordered
pizzas
being
delivered
at
all
hours
to
judges
and
even
their
grown
children
with
the
name
of
Judge
Salas’s
son
written
on
the
boxes.
The
clear
message
being
that
we
know
where
you
live
and
that
what
happened
to
Judge
Salas’s
family
could
happen
to
you.
They
told
stories
of
judges’
homes
being
swatted
on
Christmas
Eve
and
doors
kicked
in
by
law
enforcement.
They
talked
openly
about
always
looking
over
their
shoulders
when
they
go
out
in
public.
Of
never
answering
their
door.
Or
receiving
thousands
of
the
most
vile
and
threatening
emails.
These
are
just
ordinary
federal
court
judges
trying
to
do
their
jobs
day
in
and
day
out.
They
don’t
deserve
this.
Judicial
Integrity
What
also
rang
throughout
the
presentation
was
their
integrity
and
their
commitment.
They
talked
about
how
they
accepted
the
job
and
their
role
knowing
what
it
could
mean.
They
talked
of
their
determination
to
continue
making
rulings
based
on
the
law
and
the
facts
in
the
face
of
what’s
happening
in
their
world.
They
bent
over
backwards
telling
us
how
they
don’t
mind
and
expect
disagreement
with
their
rulings
and
did
not
want
disagreement
to
be
chilled.
But
they
also
made
it
clear
that
there
is
a
process
to
disagree
and
appeal.
They
also
talked
about
their
colleagues
who
make
rulings
that
may
seem
to
align
with
a
certain
ideology
when
in
fact,
they
said,
they
were
just
judges
doing
their
job.
The
level
of
respect
was
palpable
among
them
and
for
what
they
do.
But
given
all
that,
their
most
poignant
comments
centered
on
their
families.
Kids.
Spouses.
Those
who
did
not
sign
up
for
this
kind
of
abuse.
They
talked
about
the
fear
among
their
families
and
that
their
children,
who
had
no
choice,
shouldn’t
have
to
live
with
this.
Respectfully,
they
also
mentioned
their
state
court
judge
colleagues
who
by
and
large
have
fewer
resources
and
protections.
But
they
nevertheless
live
with
the
same
threats.
Why
Now?
According
to
the
judges,
how
we
got
here
is
multi-dimensional.
The
press
hyping
stories
and
rulings
and
making
the
point
of
who
appointed
a
judge.
Less
neutral
reporting
on
reasoning
and
more
on
insinuation
of
political
motivation.
Social
media
spreading
and
profiting
from
misinformation.
Fewer
reliable
sources.
A
disbelieving
and
polarized
public.
Not
to
mention
political
leaders
who
do
such
things
as
announce
impeachment
proceedings
against
judges
whose
rulings
they
don’t
like.
The
failure
to
investigate
threats
and
misinformation.
The
profound
lack
of
civility.
The
failure
of
our
education
system
to
teach
basic
civics
and
the
functions
and
benefits
of
our
three
branches
of
government.
An
ignorance
of
the
concept
of
checks
and
balances
that
are
foreign
to
so
many.
And
the
Impact
May
be
Catastrophic
The
judges
talked
about
why
what’s
happening
is
so
devastating.
The
public
is
losing
its
respect
for
the
judiciary.
Litigants
believing
if
they
don’t
like
a
ruling,
they
can
just
ignore
it.
Name
calling.
Violence.
Intimidation.
It
is
undermining
the
rule
of
law.
So,
you
say
that’s
only
for
politically
charged
cases,
right?
Not
so,
according
to
the
judges.
It’s
everywhere
and
getting
worse.
What
does
it
mean?
Our
economic
system
hinges
on
the
ability
to
get
disputes
resolved
relatively
quickly
and
with
finality
and
fairness.
When
that’s
gone,
it
means
only
the
very
rich
and
powerful
can
get
“justice”
and
do
what
they
want.
Only
they
can
get
things
like
favorable
IP
and
copyright
protections.
Can
squash
competition.
Can
ignore
rules
and
court
orders.
That’s
what
guards
our
capitalistic
economy
and
has
allowed
it
to
thrive.
And
here’s
something
else.
The
judiciary
exists
for
all
of
us
as
a
vehicle
for
dispute
resolution.
They
serve
our
needs.
They
serve
the
needs
of
our
clients.
They
are
charged
with
resolving
the
thorniest
of
legal
and
factual
questions.
But
how
long
will
the
best
and
brightest
want
to
serve
when
they
and
their
families
are
threatened
daily?
Who
will
want
to
step
up
and
answer
the
call
to
serve?
It’s
not
just
the
judges
and
their
families
that
are
threated.
It’s
our
very
system
of
government
and
social
fabric.
Let
that
sink
in.
What
to
Do?
I’ve
lost
my
share
of
rulings
from
federal
district
court
judges.
I
know
they
can
be
persnickety
and
demanding.
But
I
never
lost
respect
of
the
process.
I
never
called
them
names.
I
respected
and
followed
the
rules
even
when
they
were
hard
for
my
client
to
swallow.
So,
when
so
many
seem
to
lack
that
respect,
it
was
a
legitimate
question
that
was
asked
by
an
audience
member:
given
where
we
are
as
a
society,
can
anything
be
done?
Listening
to
the
judges,
I
think
all
of
us
in
legal
need
to
double
down
on
education
to
our
clients
and
society
about
the
critical
role
of
the
judiciary.
We
need
to
make
sure
we
treat
our
judiciary
and
each
other
with
respect
even
when
we
disagree.
We
need
to
remember
that
our
judges
are
here
to
serve
us.
That
they
are
indispensable
to
what
we
do
as
a
profession.
As
judges,
their
ability
to
speak
out
on
individual
matters
is
constrained
by
judicial
ethics.
Our
abilities
are
not.
We
need
to
stand
up
for
them.
We
need
to
push
back
on
statements
by
politicians
and
others
denigrating
our
judges.
We
need
to
say
loudly
and
often,
I
may
disagree
with
the
judge’s
ruling
but
I
respect
it.
I
know
they
were
acting
with
integrity
and
are
doing
the
best
they
could.
Otherwise,
what
we
have,
what
we
went
to
law
school
for
and
who
we
are
may
be
gone.
Thank
you
ALM,
Legalweek,
and
the
judges
for
putting
this
together
and
saying
loudly
what
needs
to
be
said.
Note:
As
many
of
you
know,
I
am
on
the
ABA
TechShow
Board.
Later
this
month,
we
will
offer
a
panel
discussion
by
the
immediate
past
ABA
President,
the
current
ABA
President,
and
the
incoming
ABA
President
on
the
rule
of
law,
among
other
things.
I
would
encourage
all
of
you
to
attend
and
to
take
seriously
the
clear
and
present
danger
we
are
facing.
Stephen
Embry
is
a
lawyer,
speaker,
blogger,
and
writer.
He
publishes TechLaw
Crossroads,
a
blog
devoted
to
the
examination
of
the
tension
between
technology,
the
law,
and
the
practice
of
law.
Effective
discovery
requires
more
than
compliance
—
it
requires
strategy.
In
this
on-demand
webinar
presented
by
our
friends
at
InfoTrack,
you’ll
hear
from
attorney
and
legal
educator
Drew
Levine,
who
provides
a
practical,
results-focused
tutorial
on
how
litigators
can
balance
expansive
discovery
rights
and
privacy
concerns
without
slowing
cases
down.
Key
topics
include:
•
Balancing
proportionality
and
broad
discovery
rights • Managing
electronically
stored
information
(ESI)
and
privacy
concerns • State
and
federal
contrasts
in
discovery
practice