A
first-of-its-kind
random-sample
survey
of
federal
judges
has
found
that
more
than
60%
have
used
generative
artificial
intelligence
tools
in
their
judicial
work,
though
fewer
than
one
in
four
use
these
tools
on
a
daily
or
weekly
basis.
The
study,
conducted
by
researchers
at
Northwestern
University
in
collaboration
with
the
New
York
City
Bar
Association,
provides
an
empirical
snapshot
of
how
AI
is
being
integrated
—
and
not
integrated
—
into
federal
court
chambers.
The
research,
“Artificial
Intelligence
in
Federal
Courts:
A
Random-Sample
Survey
of
Judges,”
forthcoming
in
Volume
27
of
The
Sedona
Conference
Journal,
surveyed
502
randomly
selected
bankruptcy,
magistrate,
district
court
and
court
of
appeals
judges
in
late
2025.
Of
those,
112
responded,
for
a
22.3%
response
rate.
The
survey
found
that
61.6%
of
responding
judges
use
at
least
one
AI
tool
in
their
judicial
work.
Of
those,
however,
few
use
it
frequently.
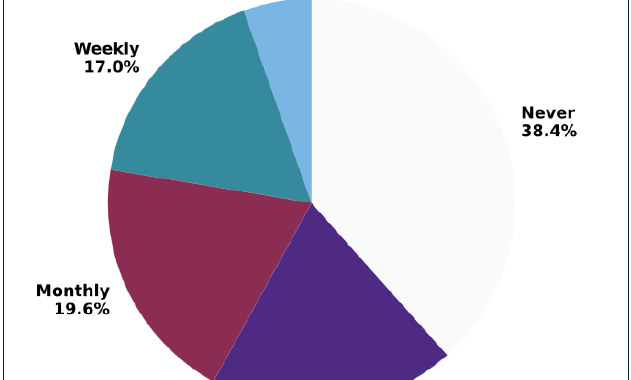
Only
5.4%
reported
daily
use,
while
17%
use
AI
tools
weekly.
Another
19.6%
use
AI
monthly,
and
the
same
percentage
use
it
rarely.
The
remaining
38.4%
reported
never
using
any
of
the
listed
AI
tools
in
their
work.
“Although
a
majority
of
responding
judges
at
least
occasionally
use
AI
tools
in
their
judicial
work,
relatively
few
report
using
AI
on
a
daily
or
weekly
basis,”
the
report
states.
“This
pattern
suggests
that
AI
is
present
in
federal
judicial
chambers
but
not
yet
a
routine,
embedded
part
of
most
judges’
decision-making
processes.”
A
Preference
for
Legal
AI
Tools
The
survey
found
a
clear
preference
among
judges
for
legal-specific
AI
tools
integrated
into
established
research
platforms
rather
than
general-purpose
AI
systems
such
as
ChatGPT.
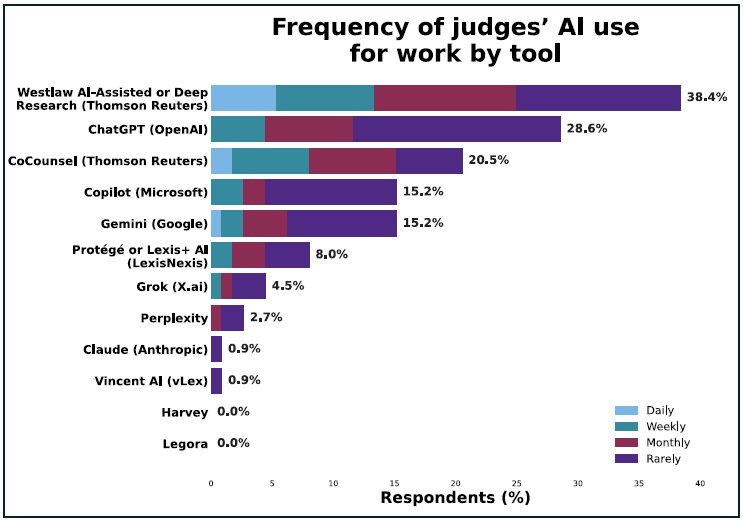
That
said,
while
Westlaw
AI-Assisted
Research
or
Deep
Research
was
the
most
commonly
used
tool,
with
38.4%
of
judges
reporting
some
level
of
use,
ChatGPT
came
second
at
28.6%.
However,
the
frequency
of
use
differs
between
legal-specific
and
general
tools.
For
legal-specific
AI
tools,
5.4%
of
judges
reported
daily
use
and
9.8%
reported
weekly
use.
For
general-purpose
AI
tools,
only
0.9%
reported
daily
use
and
9.8%
reported
weekly
use.
“This
pattern
indicates
that
vendor
familiarity
and
perceived
reliability
may
strongly
shape
which
AI
tools
judges
are
willing
to
deploy
in
chambers,”
the
report
notes.
Other
AI
tools
showed
minimal
adoption.
Anthropic’s
Claude
was
used
by
only
0.9%
of
judges,
all
at
a
frequency
of
“rarely.”
Harvey
and
Legora
showed
0%
usage
across
all
responding
judges.
Vincent
AI
(vLex)
similarly
showed
only
0.9%
rare
usage.
Legal
Research
Dominates
Usage
When
asked
about
specific
applications,
judges
overwhelmingly
pointed
to
legal
research
as
their
primary
AI
use
case.
Thirty
percent
of
judges
reported
using
AI
to
conduct
legal
research,
making
it
the
most
common
application
by
a
significant
margin.
Document
review
came
in
second
at
15.5%,
followed
by
drafting
documents
not
filed
in
cases
(7.3%),
summarizing
text
or
audio
(7.3%),
and
preparing
case
timelines
or
chronologies
(5.5%).
Notably,
judges
reported
minimal
use
of
AI
for
drafting
or
editing
documents
that
are
filed
in
cases.
Only
1.8%
reported
using
AI
to
draft
filed
documents
such
as
orders,
opinions
or
judgments,
and
2.7%
reported
using
AI
to
edit
such
documents.
This
contrasts
with
higher
rates
for
non-filed
documents:
7.3%
use
AI
to
draft
letters,
emails
or
articles,
and
4.5%
use
AI
to
edit
such
materials.
The
survey
also
found
that
1.8%
of
judges
reported
using
AI
to
“make
decisions,”
while
4.5%
reported
using
AI
to
“inform
decisions.”
Staff
Show
Similar
Patterns
Judges
reported
slightly
higher
AI
usage
compared
to
others
in
their
chambers.
While
50.9%
of
judges
said
they
do
not
use
AI
in
their
work,
a
somewhat
lower
45%
reported
that
others
in
their
chambers
do
not
use
AI.
Legal
research
remained
the
top
use
case
for
chambers
staff
at
39.8%,
followed
by
document
review
at
16.7%.
The
patterns
largely
mirrored
judges’
own
usage,
though
judges
reported
that
staff
use
AI
for
legal
research
approximately
10
percentage
points
more
frequently
than
judges
themselves
do.
Several
judges
indicated
uncertainty
about
how
their
staff
actually
use
AI.
One
responded
simply,
“I
am
not
certain
whether
they
use
any
type
of
AI.”
Another
recounted
an
incident
where
“my
law
clerk
wrote
a
memo
for
me,
and
then
after
she
finished,
out
of
curiosity,
she
asked
AI
to
write
a
memo
on
the
same
question.
Of
the
11
cases
AI
cited
in
its
version,
10
of
them
were
fake.”
Training
Gap
Identified
The
survey
revealed
what
the
researchers
describe
as
“unmet
demand”
for
AI
training
in
the
judiciary.
Nearly
half
of
judges
(45.5%)
reported
that
AI
training
had
not
been
provided
by
court
administration,
and
an
additional
15.7%
were
unsure
whether
training
had
been
offered.
Among
the
38.9%
who
recalled
training
being
offered,
a
significant
majority
(73.8%)
attended.
This
suggests
that
when
training
is
provided
and
visible,
judges
are
receptive
to
it.
Training
availability
and
attendance
varied
by
judge
type.
Magistrate
judges
reported
the
highest
rate
of
attending
training
at
40%,
followed
by
bankruptcy
judges
at
36.7%.
District
court
judges
reported
attending
at
a
lower
rate
of
16.7%.
Chambers
Policies:
A
Mixed
Picture
The
survey
found
no
dominant
approach
to
AI
governance
within
chambers.
Approximately
one-third
of
judges
either
permit
and
encourage
(7.4%)
or
permit
(25.9%)
AI
use
by
those
working
in
their
chambers.
Another
third
either
formally
prohibit
(20.4%)
or
discourage
but
do
not
formally
prohibit
(17.6%)
AI
use.
One
in
four
judges
(24.1%)
reported
having
no
official
policy
on
AI
use.
If
those
who
merely
discourage
AI
without
formal
prohibition
are
included,
41.7%
of
judges
lack
an
official
AI
policy.
Several
judges
who
selected
“permitted”
or
“permitted
and
encouraged”
described
significant
limitations.
One
wrote:
“I
have
a
firm
policy,
though,
against
AI
generating
content
of
orders,
opinions,
or
communications.”
Another
specified
that
AI
is
“permitted
and
encouraged,
but
within
very
narrow
guardrails.
Only
as
part
of
Westlaw
or
Lexis
research
tools,
and
only
to
summarize
voluminous
materials.”
Similarly,
some
judges
who
selected
“formally
prohibited”
carved
out
exceptions.
One
noted:
“My
clerks
can
use
AI
for
legal
research
(Westlaw)
but
not
for
other
functions.”
Another
wrote:
“It’s
fine
to
use
for
something
like
a
poem
celebrating
a
birthday
or
anniversary.
But
I
do
not
permit
it
for
case-related
work.”
Personal
Use
Correlates
with
Professional
The
survey
found
a
statistically
significant
correlation
between
judges’
personal
and
professional
AI
use.
The
researchers
used
a
statistical
analysis
tool,
the
chi-square
test,
and
found
what
they
described
as
“strong
statistical
evidence”
of
association.
Another
statistical
analysis
method,
the
Cramér’s
V
test,
found
a
moderate
strength
of
association
between
their
personal
and
professional
use.
Overall,
38%
of
judges
reported
using
AI
daily
or
weekly
outside
of
work.
When
asked
about
personal
AI
uses,
judges
described
a
wide
range
of
applications:
trip
planning,
restaurant
recommendations,
general
knowledge
searches,
drafting
personal
correspondence
and
household
questions.
One
judge
who
uses
AI
daily
outside
work
wrote:
“I
use
them
every
day
to
get
answers
to
questions
as
they
pop
up
throughout
the
day.
I
do
not
ever
use
AI
to
work
on
my
cases.”
One
in
five
judges
(20.4%)
reported
never
using
AI
in
either
their
personal
lives
or
their
work.
A
Split
Between
Optimism
and
Concern
When
asked
about
their
general
outlook
on
AI’s
potential
for
the
judiciary,
judges
were
nearly
evenly
divided.
Slightly
more
than
43%
expressed
optimism
(13%
very
optimistic,
30.6%
somewhat
optimistic),
while
approximately
42%
expressed
concern
(13.9%
very
concerned,
27.8%
somewhat
concerned).
Another
14.8%
were
neutral.
The
free-response
comments
revealed
recurring
themes
on
both
sides.
Optimistic
judges
emphasized
efficiency
gains
and
research
capabilities.
One
wrote:
“Summarizing
trial
transcripts
and
voluminous
documents
and
pinpointing
instances
of
specific
testimony
in
a
closed
universe
environment
is
a
huge
time
saver.”
Another
noted:
“I
believe
it
will
be
a
significant
benefit
to
conserving
judicial
resources.
So
long
as
accuracy
can
be
confirmed.”
Concerned
judges
focused
primarily
on
hallucinations
and
skill
atrophy.
One
wrote:
“The
consistent
reports
of
zombie
cases
and
other
instances
where
AI
conjures
law
or
facts
is
terrifying
and
forms
the
basis
for
how
we
use
AI
in
chambers.”
Another
expressed
worry
about
broader
effects:
“My
[spouse]
teaches
and
has
sensitized
me
to
the
harmful
effects
that
AI
is
having
on
students’
ability
to
think
and
write
for
themselves.
The
undergraduate
students
of
2025
are
the
law
clerks
of
2030,
so
yes,
I’m
concerned.”
Several
judges
expressed
mixed
feelings.
One
neutral
respondent
wrote:
“I’m
optimistic
that
AI
can
help
us
become
more
efficient
…,
but
I
am
highly
concerned
that
AI
is
causing
younger
generations
of
lawyers
and
laypeople
not
to
think
critically
and
to
lose
essential
research
and
writing
skills.”
One
very
concerned
judge
wrote:
“If
I
had
published
an
opinion
with
hallucinated
citations,
I’d
have
to
give
serious
consideration
to
resigning.”
Differences
Across
Judge
Types
The
survey
revealed
variations
in
AI
adoption
and
attitudes
across
different
categories
of
federal
judges,
though
the
researchers
caution
that
some
findings
—
particularly
for
court
of
appeals
judges,
where
only
six
responded
—
should
be
viewed
as
anecdotal
rather
than
representative.
Bankruptcy
judges
showed
the
highest
rate
of
daily
or
weekly
AI
use
at
32.2%,
compared
to
21.9%
for
magistrate
judges
and
13.9%
for
district
court
judges.
Conversely,
46.5%
of
district
court
judges
reported
never
using
AI
in
their
work,
compared
to
35.5%
of
bankruptcy
judges
and
37.5%
of
magistrate
judges.
On
outlook,
magistrate
judges
were
more
optimistic
than
concerned
(46.7%
versus
30%),
while
bankruptcy
judges
(50%
concerned
versus
40%
optimistic)
and
district
court
judges
(47.6%
concerned
versus
40.5%
optimistic)
leaned
toward
concern.
Other
AI
Tools
and
Use
Cases
When
given
the
opportunity
to
describe
other
AI
tools
and
uses,
some
judges
identified
applications
beyond
the
survey’s
listed
options.
One
judge
mentioned
using
Speechify,
an
AI-based
text-to-speech
tool,
on
a
weekly
basis.
Several
described
using
AI
for
preparing
presentations,
talks
and
CLE
program
outlines
—
activities
related
to
but
distinct
from
case
work.
One
judge
raised
a
definitional
question:
“It
depends
on
how
you
define
AI
tools.
I
assume
you’re
referring
to
Generative
AI.
Even
assuming
it’s
Gen
AI
you’re
concerned
with,
would
text
prediction
be
included?”
Limitations
Acknowledged
The
researchers
acknowledged
several
limitations.
The
112-judge
sample,
while
providing
a
foundation
for
analysis,
carries
a
margin
of
error
of
approximately
±9%
at
a
95%
confidence
level
for
the
overall
findings.
Margins
of
error
are
larger
for
specific
judge
types,
and
findings
for
court
of
appeals
judges
(six
respondents)
cannot
be
considered
representative.
The
researchers
also
noted
potential
biases
including
self-selection
(judges
with
strong
opinions
about
AI
may
have
been
more
likely
to
respond)
and
social
desirability
bias
(judges
might
under-
or
over-report
AI
use
based
on
how
they
perceive
such
use
is
viewed).
The
study
was
limited
to
federal
judges
and
did
not
include
Supreme
Court
justices,
Court
of
International
Trade
judges,
or
state
court
judges.
Methodology
The
survey
was
conducted
between
Dec.
1
and
Dec.
19,
2025.
Researchers
used
a
stratified
random
sampling
method,
selecting
approximately
29%
of
judges
from
each
category
(bankruptcy,
magistrate,
district
court
and
court
of
appeals)
from
a
compiled
population
of
1,738
federal
judges.
The
survey
featured
both
multiple-choice
and
free-response
questions
and
was
approved
by
Northwestern
University’s
Institutional
Review
Board.
Only
the
Northwestern
researchers
had
access
to
the
unprocessed
data;
other
authors
and
collaborators
received
only
aggregated
visualizations
and
de-identified
individual
responses.
The
research
was
conducted
by
Anika
Jaitley,
research
assistant
for
the
Law
and
Technology
Initiative
at
Northwestern
University
Pritzker
School
of
Law;
Daniel
W.
Linna
Jr.,
professor
of
instruction
and
director
of
Law
and
Technology
Initiatives
at
Pritzker;
U.S.
District
Judge
Xavier
Rodriguez
of
the
Western
District
of
Texas;
V.S.
Subrahmanian,
Walter
P.
Murphy
professor
of
computer
science
at
Northwestern
University
and
Buffett
faculty
fellow
at
Northwestern’s
Buffett
Institute
for
Global
Affairs;
and
Siyu
Tao,
law
student
and
research
assistant
at
Pritzker.





 Kathryn
Kathryn











{kind=link}